On asking Randy about getting recognized in public as a ‘celebrity’, he says, “Almost never, and even when it happens, it’s usually someone I know or have met, so that doesn’t really count. I don’t think it’s fair to say I have “celebrity status, especially compared to all those “social media” experts who have 100K+ followers on Twitter.”
Probably, you might also not have identified him by his name, but, what if I say, Mr. Rand Fishkin – Co-Founder and Former CEO, SEOMoz..??
Got him now??
SEOMoz is not a new name in the Digital world today and hence Rand Fishkin is a familiar face for all!
“There is a great story behind every successful individual” and this saying fits well with the life of Rand Fishkin. Like every other great personality, Randy too covered the voyage through hardships, struggle and failures in his life.. But these letdowns never stopped him and he reached where he is today
Rand fishkin SEO MOZ
Rand Fishkin – His Tough Journey to Success!
Achieving success is not a game of a day or two. Even people who are highly successful have suffered a lot in getting all they have achieved today.
When Randy along with his partner Gillian Muessig started working on MOZ, they had no idea about how to run a business. From venture capital to even the full form of MRR, they were completely blank. “You know, we just had no savviness at all about how to build revenue, how to get customers, keep them, how to maintain a financial model that had any hope of succeeding… We were just truly rank amateurs at this stuff.”
What they knew was just the expenses needed to maintain the tools.
“ All I knew was well, it cost us this much to maintain our tools, so we’d better get people paying us every month instead of a one time download, because it costs us money to keep it up. I had the most simplistic of thinking that you can imagine from a business perspective.”
Although, today SEOmoz is the world’s biggest SEO platform, it gave a lot of pain to Randy during his entire journey. Rand literally struggled with depression while building Moz. His depression made him see everything around him with negative light as all his strategies and efforts for Moz were failing. The situation got worst when Moz lost $6m in 2013. It was a heartbreaking episode for Rand.
Although, Rand is very jubilant in real life, during depression he started living in isolation, away from the limelight and even family and friends.
“When I was depressed, I really did not feel better after spending time with my friends and coworkers who were just like, “everything’s fine, Rand, look at these amazing thing you built. What are you complaining about? It’s going so well, so you had one misstep, it’s going to turn itself around. It’s not like you’re bleeding money, you didn’t have to fire anybody. What’s your problem, Rand?
I hated that. HATED it. It just bugged the shit out of me.
I’m having a visceral reaction just remembering that now“.
What shattered Randy was the public response he received when Moz was in loss.
“Folks were like, “yeah man, this is complete shit. I can’t believe we fucked this up, you fucked this up, it’s gotta get better, we’ve gotta improve it, we need to work on this, this is just terrible and I understand how badly you feel.”
But…… things really changed! Randy finally made efforts to fight his depression and come back. His supporters, friends and mentors who trusted him brought him back into action.
“The thing that helped me the most was hanging out with friends and folks who either had depression before, or understood that anxiety and could commiserate. Honestly that was way more helpful, way more comforting than “everything will be all right.”
People like Ben Ha (of The Cheezburger Network) who have been through struggle and depression, greatly inspired Rand.
“I really liked spending time with him. I like spending time with him now, too, but it was just great to have that feeling of not being alone. Of not feeling like “the rest of you are crazy, why can’t you see this terrible thing for what it is?”
And finally, his depression began to fade with a silly event that he had.
“The moment of change happened after a doctor’s visit, in a very weird, inexplicable way. A few months prior to the doctor’s visit, I had tried a chocolate truffle laced with THC (don’t panic, personal Marijuana use is legal in Washington State). I’ve had sciatica in my left leg for years. For 6 hours after I tried the pot truffle, I felt horrible – crazy paranoid and high and awful. Then, for the next 3 days, my leg didn’t hurt at all for the first time in six years. I told my doctor about this, and she said “the funny thing is, Marijuana doesn’t have any pain-killing properties. It just lessens tension, anxiety, and stress for some people.”
Moment of epiphany! My pain is tied to anxiety and stress (probably) and since I’m not particularly excited about trying pot truffles again after those first 6 hours of hell, I need to work on those things in order to fix my leg. And not just my leg, There’s likely all sorts of maladies, mental and physical, that I might suffer in years ahead if I can’t get this under control. That night, I felt different. I looked at our daily numbers email in the morning, and I didn’t come up with some reason in my head why they were bad even though they looked good. “
The Bottom Line
Despite of having specific goals in life, we tend to fail often. This is because it’s not difficult to set goals; it’s difficult to fulfill them. People get into depression because they fear failure and loss, just like Randy. He was so much moved by the continuous losses that he got clutched in despair and heart-break. But, that one event, though weird, changed Randy’s life, bringing him back in his pace and getting him the position he earned today. It’s only a momentous impact that can shake and wake you!
Don’t fear failures. They are the stepping stones to success. The more you fail, the more you learn and the better you achieve. Try to learn from your pain. Just think, what are those things that can ease your pain and anxiety and you’ll find several things around.
And as said, Big things come in small packets…. Your journey of endless failures and little gains… though may take time… but definitely will lead you to your ultimate goal.
In my 10 years long career, I have read lot of books and certainly Sean V Bradley “ Googleopoly book I recently bought was one of the good buys that helped in writing and practicing this strategy for video optimization.
Especially, the video optimization chapter was the best one, though a basic start but the examples are good enough to keep you glued to the book and I have been using the same in my small 40 people digital marketing company for enhancing their skills as well. You can see the short video below as an example I used in my company:
To be honest, not only the book, video and the PDF will help you get business from you-tube. They are just basic set ups that are necessary to get the best out of your video optimization campaigns. You will need to have a perfect strategy in-place i.e. an astounding idea, perfect study of your target audience, paid campaign if required and an innovative mind on how to produce share and likes for your video, in simple words, “to make it viral you need to be creative”.
Try out for Results of Video SEO in 30 days:
Example 1 for Video Optimization:
I had done video optimization 3 years back and was able to rank most of the videos for New York based handyman client and honestly speaking, things have changed a lot since then, the way Google rank videos now is a way different then it ranked 3 years back.
So for 2015, What can be the right strategy?
What I Feel –
“Well till you are not in the playground yourself and you do not have the right stats, you just can’t predict things.“
Following that idea in my mind, I have started trying the same as below myself:
I created a video for one of my client. “Apixel.com.sg”
Time Tenure till now: 30 Days
Video Created and Used:
Targets to Achieve for the Video Optimization Campaign:
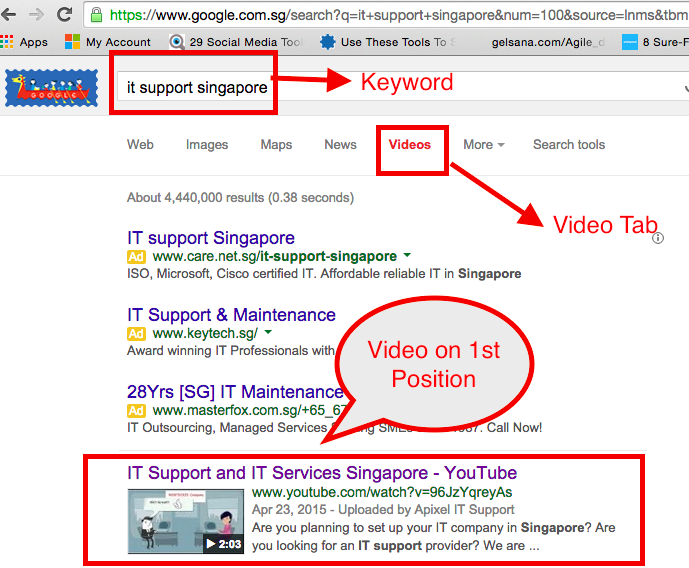
To rank “IT Support and IT Services Singapore” phrasal keyword on Google.com.sg on search engine in Organic and Video Tabs.
To rank “IT Support Singapore” for an exact match keyword on Google.com.sg on search engine in Organic and Video Tabs.
Another target is to rank the video for “Brand Searches” i.e. “Apixel IT Support” keyword on top 5 positions.
Note: Keyword selection is done, according to analytical stats and SEM Rush tool.
Note: We already rank on TOP 1st page for Organic and Local rankings for the client on the keywords so now the main JOB is to rank the video in Top 100 and then in Top 10.
Results Achieved so Far for the Video Optimization Campaign:
Brand Keyword “Apixel IT Support” – Top 5 positions – Achieved
Video Optimization Example for Brands in 2015
IT Support Singapore – 1st Position on Video Tabs – Achieved and 116th Position on Organic Ranking – In Progress
How to Optimize Videos in 2015
IT Support and Services Singapore – 2nd Position on Video Tab Rank – Achieved and 120th Position for Organic Ranking – In Progress
So, the best part is that with-in 30-45 days of small part of optimization gave me some effective results. I cannot share the traffic data of my clients but can give you an idea that my Google analytical goal triggered results.
Moving ahead, I will be updating the results for the same by further optimization every month.
If anyone followed the same strategy and have better ideas please share your comments below.
Example 2:
Client: CotyTech.com
Challenge: To rank and optimize current videos for keyword “Apple Monitor Mounts”
‘With great power, comes great responsibility’ – this quote seems perfectly suited for Google. The search engine giant has outshined all players in the race by a significant margin by continuously providing unprecedented services. Google keeps on incorporating new features to better a user’s search experience so that they can get access to more useful and appropriate data in the least possible time.
Google’s Freebase acquisition is one step in this direction that allows people to access relevant and commonly available information more effectively. This is why a small module with a summary immediately appears on the R.H.S. of the search result page when you search for a person, place or thing.
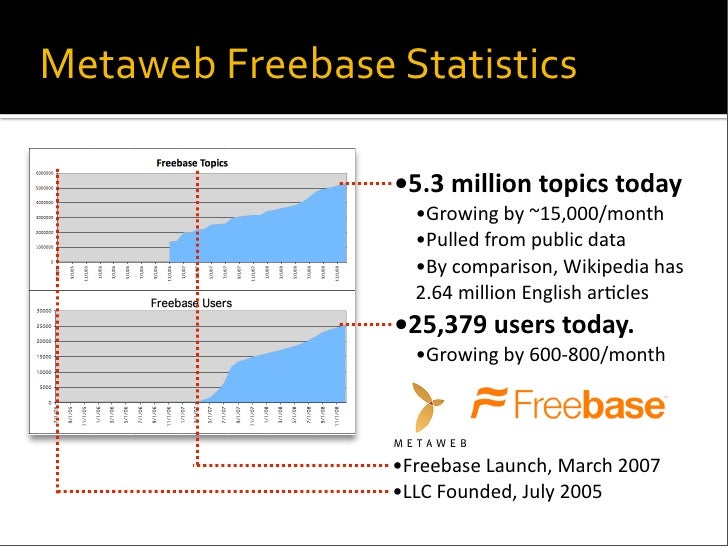
Freebase is a collaborative graph database for structuring knowledge of people looking for information about a particular person, thing or place on the internet. This ingenious open-source, shared database is the brain-child of San Francisco-based startup Metaweb Technologies, Inc. The company was founded by Robert Cook and Danny Hillis in 2005, and is now an integral part of Google since 2010.
It’s a community-curated database of more than 12 million well-known objects including movies, books, TV shows, locations, etc., which combines structured and unstructured data, maintains the association between them and finally uses it to show Google search results based on both kinds of data. Being an open-source platform, it is available free for use by developers and encourages other companies and users to contribute to enhance its knowledge base of metadata.
How to add your brand/business to Freebase
Freebase swings into action as soon as you enter a search query, and it collects information from various reliable sources such as, Wikipedia and displays it as Knowledge Graph.
If you are the owner of a company and want information about your company/brand to appear on the Knowledge Graph, follow the steps I’ve listed below and see how using Freebase the search engine giant provides better and more contextual results for your brand.
Knowledge Graph says the 3rd most important fact about Nietzsche is that he starred in ‘Road to Rio’ & ‘Carbon Elvis’ pic.twitter.com/jruHS8evng
As the Freebase is a Google company, it prefers you sing into it with a Gmail account. If you already have a Google account, then you can directly jump to the sign in/sign up button on the website and register.
Step 2 – Brand listing
If you have a Wikipedia page for your brand, possibility of your brand already being listed on the Freebase is high, since (already mentioned above) it uses information from reliable sources. If you’re not on Wikipedia, then don’t worry, there are numerous topics listed under Domain bar to choose from using which you can describe your brand easily.
After clicking on a category listed under the ‘Domain,’ you will see various types. Choose one that suites your business and proceed to create a topic for it. Clicking the button will activate the ‘gear icon menu’ on the R.H.S of the top bar. Enter the name of your brand and click ‘Create.’
Step 3- Business info
Your business has been listed on the Freebase successfully. Now you need to enter more details about your brand. For that you need to add new value listed under the ‘Topic’ module. You can further edit (add or remove) the information by making changes in the ‘Add Type.’ Enter the type of your brand, business or services you offer. ‘Assert this type’ Freebase pop-up will appear on your screen. Click ‘yes’ to continue.
Step 4 – Enriching your entities
Other important information you need to update for your brand is the logo, general overview, establishment date, name of the founding member(s), business headquarter, official webpage, social media links, etc. And, this is how search result for your brand Freebase will show to a user.
Why Freebase?
That’s all you need to get listed on the Google’s Freebase. But, one question that might be making high tides in your mind is ‘why you need to list your brand on Freebase.’ Okay, here I will try and acquaint you with the answer –
Brand image
We know the fact that having additional information and multimedia about your brand makes you look more reputable in the eyes of the users searching for your brand on the internet.
Free Ad space
This is the best advertisement spot Google offers to the brands. If you are right with the process of adding your brand to the Freebase, you are going to get almost half of Google’s search result page (SERP) for free.
Sustainability
Given that Google keeps enhancing its search algorithm, new updates keep coming in at any point in time impacting search engine rankings for your brand. However, the visual elements Freebase offers with the help of Knowledge Graph can help you stay connected to your potential customers.
Here-in the article, I have tried to familiarize you with Freebase, and how you as a business can use it for your advantage. In case there is something that keeps you begging for more, leave a comment and I will respond to your query. However, on the basis of a recent (official) report surfaced on the Freebase’s Google Plus page, Google is planning to shut down Freebase, but will continue to offer access to Knowledge Graph.
What concerns will it raise?
Following this move, Google will integrate huge Freebase database into Wikimedia Foundations’ Wikidata and the project will be shut down as a standalone entity in mid-2015. Freebase will become read-only on March 31st,2015 and a new API for entity search powered by Google’s Knowledge Graph will be introduced. By the end of June 2015, the Freebase website and APIs will be closed and the final dump of Freebase data, which is offered under a Creative Commons Attribution License, will be released.
This, for sure, is the gentlest retirement of the service ever done by Google, and it would be too early to be judgmental about the decision as one API takes a backseat, and another is ready to enter the service. But, my biggest concern, as a digital marketing expert, is how accurately the data will get updated and transferred from one platform to another. Will the same volunteers work in the Wikipedia community? What would be its impact on Knowledge Graph, good or bad? If you are also concerned about the change, then leave your feedback in the comment section below.
A lot of us out there in the SEO world are often wondering whether or not is it correct to use Wikipedia for SEO purpose. If you ask me, my answer will always be – yes!
Wikipedia undoubtedly is amidst the most visited websites on the internet. Its importance as an authority website is unparalleled. At this point it is really worth pondering how many times Wikipedia shows up in the first three or four search results on Google.
It provides unbiased and near correct information to millions of visitors every day. Wikipedia is therefore a major online traffic source, which is waiting to be used for their advantage by SEO experts. Using Wikipedia for SEO is not as easy as it may seem, you cannot just jump over to Wikipedia and check how many times you can stuff in your links in different articles.
Yes, Wikipedia is one of the finest and most effective link building sources out there, but before you can use Wikipedia to your advantage, there are many things that you need to keep in mind.
Wikipedia is basically a non-profit organization, so it doesn’t work for financial gains. Its primary objective is to provide readers with unbiased, neutral and accurate information. Studies have revealed, information on Wikipedia is nearly as accurate as Encyclopedia or Britannica and that there are billions of users on the website. The stats are good to suggest Wikipedia as an online information giant
Wikipedia doesn’t give out any link juice; all the links on Wikipedia are “nofollow”
Wikipedia does not want you to add links with which you are personally associated with you in any way
Wikipedia can add your site to spam list if links to your website are continuously added to articles on Wikipedia
Basically put, Wikipedia backlink will not add value to your site. But yes, you can still gain with exposure and keyword ranking. Most Internet Marketing experts, like myself thus suggest:
“Value is not really the question, it’s how you get your links on Wikipedia pages to benefit from other things.“
When it comes to ranking for a specific keyword, your website may not rank well for it, but your Wikipedia page with a link for the keyword will be able to rank fairly high. This does not mean you start creating Wikipedia page for every keyword, it is only beneficial if it happens organically. The main focus of an SEO professional should be to add content, and not links. Links should be secondary to content, especially when you’re dealing with Wikipedia.
The content you upload on Wikipedia should be unbiased and completely accurate.
Start by editing few related articles and then move to the target article.
When adding links, be inconspicuous and focus on linking multiple website.
Do not stick to adding links to your website alone, try and include links to few other credible sources as well.
It is also advisable not to try and add all your links at once, it should be a gradual process and should look organic.
Anyone looking to create a brand new page on Wikipedia must proceed with caution. A Wikipedia page for your company, brand or agency is extremely valuable; it can lend credibility and make you reachable on the internet. Moreover, customers searching for you on
Wikipedia feel impressed and consider your organization to be big and legitimate. Wikipedia encourages new pages on brands, which have not been written about previously. But the brand or company you are writing about should have history of being in mainstream media and the evidence should be available online.
Most SEO executives must have tried to create new pages and place their site’s link(s) on it. In most cases, fanatical Wikipedia editors must have removed it. Why does this happen? It is because the external link you provided is of little use to the community and only benefits you.
You should not let this deter you. If you have a website that can be recognized as a resource in its domain. And if you see that Wikipedia does not have a page on the topic you cover, you should venture into creating a page and gain SEO benefits from the link(s) you place in the article.
Here is how you can get down to create a compliant Wikipedia page:
Become a trusted contributor: You cannot get around this, if you are planning to make an edit to existing Wikipedia content, or you plan to add a new page; you need to sign in as user.
Login: After creating an account, login to Wikipedia. You can do this directly if you have an existing account. Search if the page already exists: Before getting down to create a page, search Wikipedia to see if the page you plan already exists. If it doesn’t exist you can go on to make the page; but if it is already made you can see the information, read it and edit if necessary.
Category: All pages on Wikipedia should be placed in one category at least. The easiest way to find a relevant category for your page, search for similar articles and copy the category from there. You can go to the end of the page, to add category module and select your category there.
Include multiple references: Wikipedia says it’s not a dictionary, so it requires every page to have more than a dictionary-style definition with one or no reference. It is advisable to cite at least 3-4 reference links (to credible sources) on a new page. Moreover, including the reference within the article, listing out references at the end of the articles is not considered a good practice by Wikipedia editors.
Links other pages in Wikipedia: It is encouraged and expected of you to add references (links) of other pages within Wikipedia, which have relevance to your page content. More detailed process of creating a page can be found here, I’d like to inform that people will edit your page, sometimes in ways you may dislike. Though, Wikipedia has a policy to let you discuss if you disagree with some change, but it may not have a desirable effect on the link you had included. So, what’s the best you can do to ensure Wikipedia page retains the link to your website. The idea is simple – ensure the page linked is useful to any visitor landing on the page through Wikipedia, make sure it does not contain anything promotion or commercial. There are several reasons for your article, or the link in it, to be removed from Wikipedia, the main thing is to ensure that there is a level of neutrality. Do not include anything promotional about your brand or company on the page.
Different types of Wikipedia pages
Individual, group, band, company, agency or brand, just about anyone can create a page on Wikipedia. Every page is different from the other, but there is a catch – a page should be neutral, verifiable and should not be promotional. Any page which does not comply with Wikipedia’s terms and conditions or is found to be unworthy of inclusion can be removed from the website as per the site’s deletion policies.
Without saying, Wikipedia seeks neutrality. Every page or article on Wikipedia should be editorially neutral. The page cannot take sides of the organization, brand or individual it discusses. It should report both the good and bad about the topic from reliable and verifiable sources. The page cannot be promotion and must only contain factual information.
When you write an article about yourself, your agency, organization, company or brand, you have no right to control its content or the right to delete it outside Wikipedia’s normal channels. It is exciting to have an article about yourself, your company etc. on Wikipedia, but it cannot be your sales brochure. The article should not be there to promote, but to tell the world about the topic’s neutral point-of-view. Include your links only if they are useful to the community and not just you (for the sake of promotion, you can only include the link to your website).
It is because of this, most SEO experts, will tell you to ask someone with no obvious ties with you, or someone who has good reputation with Wikipedia to create a page for you or your business. This will present a neutral viewpoint.
Link between Google Knowledge Graph and Wikipedia
Google formally launched its Knowledge Graph back in 2012. The new technology which appears as a box on the side of Google’s traditional search result, providing interesting facts about people, company, brand, place or thing. Google Knowledge Graph picks out most important facts for each search query, to show the visitor information they are looking for in a snippet.
The introduction of Google Knowledge Graph (or Graph) is seen to have an effect on Wikipedia. It is believed that the free online encyclopedia lost about 10 percent of its page views in 2013. The Wikimedia foundation website shows that page views on English Wikipedia declined by close to 12 percent in the period between December 2012 and December 2013. The report brings out a finding that believes when people can get their answers from the search page itself, why would they want to click Wikipedia page for it.
Google Knowledge Graph Search ensures that people don’t have to click further than the search page when they are searching for companies, people, big brands etc. It may be an outside reason for decline in Wikipedia’s viewership, but there is no denying that Graphs (don’t have a box for everything). For information on most things, you still have to go to Wikipedia.
Using Broken Link Building for Wikipedia
When it comes to backlinks, just like any other website, Wikipedia also has broken external links site wide. Wikipedians define “dead link” as link not active. This means the link needs to be replaced. For SEO experts it is a great opportunity to find dead links as it can be a new backlink opportunity. You can find all articles with external dead links here. WikiGrabber is another good tool to help narrow your search for dead links.
Broken Link Building benefit
It is one of the most interesting white hat link building tactic to look up Wikipedia for all dead links. If you have a reference to the dead link, grab the opportunity and get a nofollow link from one of the most trusted website out there. You can email the site owner telling them their links with relevant Wikipedia pages. This will benefits SEOs in two ways:
The website owner is flattered because you have helped them fix a broken link
And you have a new backlink
“Wiki Grabber” – Introduction to tool and its advantages
Wiki Grabber, as discussed, is one of the finest tools to search for dead links. The tool is a quick way to find Wikipedia pages for non-active links, which need citations and/or dead link replacement. As an SEO you can use Wiki Grabber to your advantage to:
Instantly reach Wikipedia pages with broken and inactive links
Wikipedia refers to broken links as dead links. SEO can easily find the dead links on the page
Once the dead links are found, they can be replaced with your link
Conclusion
Wikipedia, we have come to understand, is the biggest authority websites on the internet. Therefore, the best thing any SEO can do is, create backlinks from Wikipedia. Just because Wikipedia links are nofollow, shouldn’t be a reason to believe that links are not valuable.
Imagine the time when people first saw a motion picture, complete with sounds and moving pictures. They must have been surprised to the core when they happened to see movie characters and landscapes come alive on the screen. It was the “projector” that did the trick.
Multiple, layered outcomes of a series of sequential actions in a video game were no doubt predefined by the software program but users did find themselves highly entertained due to the increased involvement.
As the computer science took center stage in all sectors including defense, entertainment, education, healthcare etc., several state funded and private organizations began allocating funds for research on Virtual Reality.
They knew the applications of a viable VR technology were immense. While some companies like Nitendo launched VR games way back in 1990s, several others jumped in and spent millions of dollars on VR R&D.
VR games were launched in huge numbers over the next few years and other organizations too found ways to make use of the advanced VR technologies.
Here’s a fine example of immersive virtual reality:
Advancements in 3D and other such technologies have now made it possible to pass on the fruits of years of research to common people in the simplest ways imaginable.
In order to make VR more accessible to the world (as it required expensive hardware and software), a team at Google decided to develop a product that would provide VR experience right in the mobile phone
Google gifted an Android App titled “Google Cardboard” and a “cardboard” (fundamentally an Origami model) to developers this year at a conference.
Joined together, an Android Phone with the “Google Cardboard” app and this cardboard literally transformed itself into a basic but impressive virtual reality headset.
No, it’s not perfect but you do get the idea where we’re headed, right?
Can you imagine just how drastically (and for good) the mobile experience will change when VR in mobile becomes mainstream!
Consider This:
A mobile virtual world made up of the following:
A mobile device (which you can easily carry around easily)
A supplementary component to make it VR-ready (preferably less bulky than that of Oculus; its great work though!)
Superior Virtual Environment (preferably better than that of Google Cardboard)
VR, I think, may take the world by storm in not so distant future. The fact that technology giants like Google are keen to take the smartphone revolution to the next level by integrating VR technologies with mobile operating systems goes on to prove just that.
I would still want to hit the road for a refreshing bike ride but 3D shopping on my mobile, I’m game for that!
Computer science has for long made extensive use of “entities” and “relationships” for defining different data sets and key rules that govern their associations. Now, SEO and content writing professionals too may have to learn a thing or two about these concepts.
Let’s go through the basics first.
What is An Entity?
Something that can exist independently in its entirety can be termed as an entity.
So, your name is an entity and so is the title of this post. Any noun you can think of can be an entity.
What is a Relationship?
Multiple entities can be related to each other. These associations are known as ‘relationships.’
What is entity relationship model?
A Sample Entity-Relationship Diagram
entity relationship example
While ‘Writer,’ ‘Consumer’ and ‘Novel’ are entities here, they are related to each other through relationships named ‘Creates,’ and ‘Buys.’
This simple concept, enriched by “roles” and “cardinalities” forms the basis of Relationship Database Management Systems (RDMS).
What’s in it For SEO Experts?
If you are an SEO expert, you may now need to get into the basics of how relational database systems work or how you can use ER diagrams.
What should be of interest is the fact that Google has recently secured a patent that revolves around such entities.
In this case, Google has used the term “search entities.”
The Internet is growing bigger and search engine giants, well, smarter. The next big thing happening after Hummingbird, it seems, is Google taking “search entities” quite seriously.
Google’s Knowledge Graph, for example, is in fact an “entity graph.”
In near future, Google may use the “search entities” to a great extent to correlate different pieces of information that otherwise appear disconnected to a bot.
It’s Not a Recent Development
Google has been of course trying harder each year to better serve the end user as the Internet grows in size. If Google didn’t update its search algorithms every now and then, it would just fail to provide “relevant search results” due to the sheer size of the Internet.
Providing relevant results is Google’s core competence and there’s no way the company would want to lose out on that. It wants to ‘answer’ everything that billions of people want to ask it and do so in a manner that no one else can.
Back in 2010, Google acquired Metaweb, a company that had created a fine system of indexing “named entities” on the Internet.
A “named entity” is a specific place, person or a thing. Cristiano Ronaldo, Brazil and Football, for example, are “named entities.” Each of these named entities is given a unique ID.
Equipped with a database of tagged data (named entities) created by Metaweb, essentially a semantic search startup, Google was in a position to improvise it further and ultimately make it a part of its search engine offerings.
Today, when you search for Bob Marley, you’re shown some highly customized results because Google already has information ready to be served. “Bob Marley” in this case, is handled as a “named entity.”
Example Google Knowledge Graph
Not just Google, other search engines are using such entities too. According to an internal study carried out by Microsoft, as many as 20 to 30% of all search queries processed by Bing Search were just named entities. The study also pointed out that close to 71% of all queries submitted to Bing Search had named entities in search strings.
Does that ring the bell? It should!
Search Entities – How Google Can Use Them
By successfully correlating billions of disparate “search entities,” earlier identified by making use of metrics such as keywords, images, meta tags, back links, anchor text, social signals and more recently authorship, Google may soon be in a position to further improvise its search algorithms.
Imagine how page ranks of many websites may change (for better or worse) if Google bots can effectively correlate specific information about different people, places and things.
Let’s say you create a new website on Bob Marley and make it a complete resource, by assimilating unique and high quality content as well as other information including the songs, wallpapers, videos, graphics, books etc.
Earlier, it would have been pretty hard for you to get it ranked well. It would take great effort because of highly competitive keywords. But once “search entities’ begin to play a bigger role, it would be a different ballgame.
Search Entity = Bob Marley
Related Search Entities = Songs, Music, Awards, Tours, Biography, Books, Articles, Images, Videos and so on.
If the list of “related search entities” is available with a (more) intelligent bot, do you not think it will begin to rank pages differently than how it is possibly done right now?
With “search entities” Google may be able to make some sense out of the unstructured data on the Internet. The outcomes will directly impact page ranks of websites crawled by the search engine.
What are you selling on the Internet? What are your products known for? Are you targeting a specific place? What is that place known for?
All such questions and a whole lot more may soon become more important than ever for internet marketers!
The task of an SEO is to polish the available content to see that it reaches high ranks in the popular keyword searches. However, it is not really possible for everyone to rank on the first page of the search engines because search engines frequently change their algorithms to penalize SEO oriented sites from faking the system. As search engines resort to semantic search, SEOs are steadily changing their ways and have begun using semantic SEO as the way. Semantic SEO sends more relevant search to the search engines so that your product or services ranks high in the query that is best suited for your offer.
Semantic search and semantic SEO
Semantic Markup by NY Times
Semantic SEO is one step ahead of the SEO techniques of yesteryears. Semantic SEO is fairly new web marketing technique but is fast growing in conjunction with large scale SEO perhaps for the fact that it so ably combines the facets of SEO with semantic web technology and semantic search – which instead of using keywords as the core for search results, uses searcher’s intent and meaning of the query.
Semantic SEO therefore, besides the normal focus on the user’s keyword search and links also focuses on the user’s intent and meaning of the query to provide best results on search engines.
So, when it comes to semantic SEO it becomes all the more important for retailers, bloggers, news websites, video web pages, contact, product and medical data information providing website etc. to rethink their focus on vocabularies and syntax of the structured data to rank high on the search engines following the semantic search technique.
Good Relations Ontology
It is known that structured data is responsible in sending meaningful information of data on the webpage to the search engines and other data consumers in a way that is best understood by them. There are many vocabularies and syntax that actually make a much needed difference in the structured data, but the most important that also helps in semantic search and SEO is the GoodRelations ontology or schema.org markup in RDFa or Microdata syntax.
GoodRelations ontology or schema.org in RDFa or Microdata syntax are the most powerful and effective vocabulary and syntax that can be used to send rich description of all details of products and services of a webpage in a way best suited for search engines, web browsers, mobiles applications etc.
Therefore, its believe that if a GoodRelations is used in the markup on the website then search engines, mobile apps etc have a better chance of recognizing you in the search results, which can directly increase the number of users visiting your site from the search engines. This is the reason SEOs are beginning to utilize GoodRealtions ontology.
Semantic Markup
Vocabularies and syntax mentioned above for structured data can be summed up as semantic markup. Because semantic SEO involves inclusion of semantic markup in the web page to enhance meaning of the page and make it easily comprehendible to search engines, it becomes necessary to understand what is Semantic Markup?
Semantic markup is a way to assist search engines, browsers and apps to identify the information on a web page in a language that they can easily understand. Presently the most useful semantic markup formats are RDFa and Microdata, and semantic markup is best defined as using HTML tags, which offer every clean codes that are not only easy for humans to understand and right but also for the search engine algorithms to comprehend. A reason SEOs and developers love it and semantic search recognizes.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}